Третьего октября 2020 года состоялся отборочный тур M*CTF для студентов московских ВУЗов и не только. На соревнование зарегистрировалось около тысячи пользователей в составе почти трех сотен команд. В этой статье мы расскажем об опыте, который мы получили, и о трудностях, с которыми столкнулись при организации такого ивента.
Инфраструктура
Вся инфраструктура соревнования была развернута в Google Cloud на трех хостах. На первой машине была развернута борда, на двух других запускались таски, имеющие серверную часть. От этого момента и далее под словом “таски” будут иметься в виду именно такие.
Для запуска тасков на двух оставшихся хостов был поднят Docker Swarm, где одна нода выполнял роль “менеджера”, другая — воркера. Такая архитектура позволила контейнерам динамически размещаться на том хосте, где было больше ресурсов для запуска, а пользователям — получать доступ к сервисам, запущенным на любом хосте, при обращении к одному из них. Это позволило иметь единую точку входа для пользователей.
На менеджере был поднят Gitlab Runner, автоматически собирающий и деплоящий таски в docker stack при пуше. Для переноса образов на вторую ноду использовался Google Cloud Container Registry, в который пушились образы после сборки, а docker stack deploy вызывался с опцией --with-registry-auth.
В DNS были добавлены две записи:
1. mctf.online — указывает на ip хоста с бордой. 2. *.mctf.online (любой поддомен) — указывает на ip менеджера.
Такое устройство позволило иметь каждый таск на своем домене, размещая их на любом хосте в сети docker swarm, и не прописывая hostname каждого таска вручную.
Можно выделить три типа тасков:
TCP-таски
HTTP-таски
Таски с особыми условиями
TCP-таски — это обычные docker контейнеры с проброшенными наружу портами. Благодаря docker swarm, к ним можно получить доступ при обращении к соответствующим портам на одной ноде, где бы они ни были запущены.
HTTP-таски работали немного иначе. Доступ к ним предоставлял traefik, работающий как прокси, и перенаправляющий запросы к нужному сервису внутри overlay сети, объединяющей traefik и всё http-таски. Нужный сервис определялся на основе значения заголовка Host, и поэтому все таски были доступны на красивом 80 порту со своими уникальными доменами.
Некоторые таски невозможно разместить ни одним из описанных выше способов. В нашем случае таким был таск Around the world in 10 minutes, в котором использовался реальный ip пользователя, и поэтому его нельзя было разместить в сети докера. В качестве исключения он был запущен на менеджере в обычном docker-compose с network_mode: host.
Проблемы и решения
При организации такого крупного соревнования, нам пришлось столкнуться с несколькими проблемами. Некоторые из них были вызваны ошибками планирования, другие — непредвиденными обстоятельствами. Ниже я расскажу о каждом таком случае, и о выводах, которые мы сделали.
Исходные данные:
285 команд
936 пользователей
Более 300 посетителей на сайте одновременно (в пике)
Борда: n1-standard-1 (1 vCPU, 3.75 GB memory)
Менеджер: n1-standard-1 (1 vCPU, 3.75 GB memory)
Воркер: e2-standard-4 (4 vCPUs, 16 GB memory)
Планируйте нагрузку с запасом
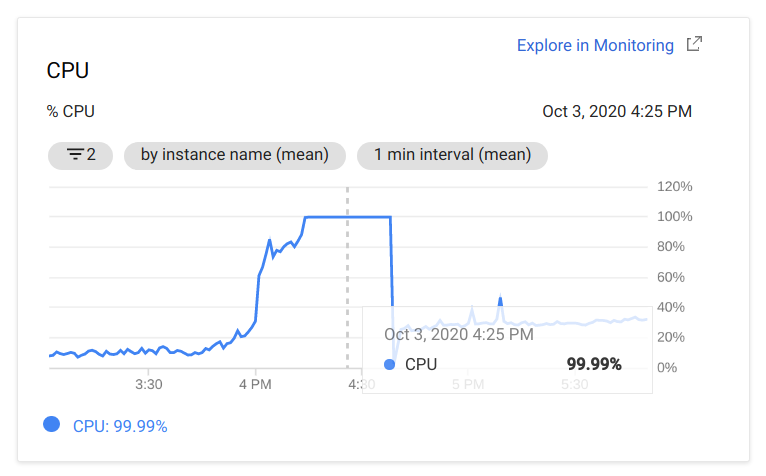
Вскоре после начала соревнования в 16:00, пользователи начали жаловаться на падающую борду. Мы не рассчитали нагрузку, которую сгенерирует такое количество пользователей, и в результате в первые 40 минут можно было наблюдать такую картину:
В 16:37 мы перевезли борду на хост e2-standard-4 (4 vCPUs, 16 GB memory) с сохранением ip, и проблем больше не возникало.
Вывод: планируйте нагрузку заранее, и берите с запасом. Лучше немного переплатить, чем переподнимать борду.
Проводите стресс-тестирование
Всего было два проблемных таска, на которые жаловались игроки: secnote и opnc. В обоих случаях проблемой были ошибки при разработке.
В secnote для работы с БД не использовался connection pool, и поэтому при большом количестве запросов через какое-то время таск переставал работать. Проблему пытались исправить несколько раз, и до конца решили только к 11 вечера, почти полностью переписав таск.
В случае opnc проблемой стала используемая библиотека websockets, используемая для работы с вебсокетами. По какой-то причине, при большой нагрузке она переставала держать подключение, и у участников отваливалось соединение. Проблему решили, перейдя на aiohttp, но сделать это удалось только к вечеру, по причине, описанной в следующем пункте.
Вывод: тестируйте таски под нагрузкой, причем дольше, чем 5 минут.
Распределите задачи заранее
В день соревнований выяснилось, что разработчик нескольких тасков ушел на работу, и не может контролировать их работоспособность. Мы не убедились, что все разработчики могут находиться за компьютером во время соревнований, так как ожидали, что это будет очевидно само по себе.
Вывод: убедитесь, что все знают, что делать
Прописывайте лимиты для контейнеров
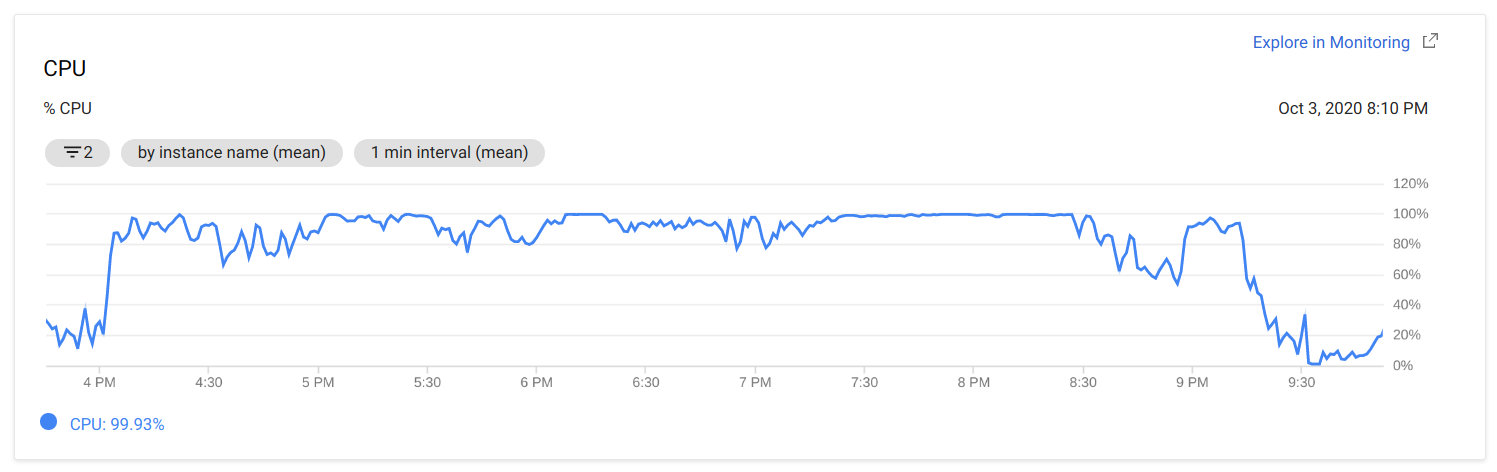
Сразу после начала соревнования, нагрузка менеджера начала приближаться к 100%. На работу большинства тасков при этом никто не жаловался, так что мы не слишком волновались, но планировали ночью, когда онлайн упадет, переехать на более мощный хост: e2-standard-4 (4 vCPUs, 16 GB memory).
Примерно в 21:20 у нас упали все таски. Исследование машин показало, что оба хоста (менеджер и воркер) работают под нагрузкой в 200+ задач (согласно команде uptime), а вскоре менеджер перестал реагировать на команды. Конкретных причин мы не знаем до сих пор, так как в логах не было ничего подозрительного, но это была отличная возможность переехать на более мощный хост раньше времени, что решило проблему с нагрузкой до конца соревнования.
Мы считаем, наиболее вероятная причина возросшей нагрузки — форк-бомба, запущенная в одном из тасков на RCE. В контейнерах у нас не были настроены лимиты CPU, что допустило такую возможность.
К сожалению, при переезде на более мощное железо у менеджера, а значит и у всех тасков, сменился ip, что вызвало проблему, описанную ниже.
Вывод: тот же, что и в проблеме с бордой. Берите железо с запасом, и прописывайте лимиты.
Готовьтесь к неожиданным изменениям инфраструктуры
В результате переезда на новое железо, у хоста, который служил входной точкой для пользователей, сменился ip. Мы сразу же поменяли DNS-запись, но для обновления кэша DNS-серверов нужно время. На DNS-сервере Google (8.8.8.8) запись сменилась почти сразу, но некоторые пользователи начали жаловаться на недоступность тасков.
Мы выпустили в группе в Telegram рекомендации по адаптации к новому IP, и повторяли их в ответ на каждую жалобу, но у некоторых пользователей проблемы сохранились вплоть до следующего утра.
Как выяснилось впоследствии, у DNS-записи для поддоменов стоял слишком высокий TTL — 24 часа. Это не позволило нам быстро обновить IP для всех пользователей.
Вывод: ставьте низкий TTL у DNS-записей на случай непредвиденных обстоятельств.
Реалистично оцените количество решений
В игре использовался алгоритм скоринга, взятый отсюда: https://github.com/CTFd/DynamicValueChallenge. При расчете параметров мы посмотрели на количество зарегистрированных команд — около 250 на тот момент — и предположили, что из них хотя бы один таск решат около половины, и минимального количества очков таск должен достигать при достижении количества решений в 75% из них. Результат мы округлили до 100 и установили таким параметр Decay.
Практика показала, что мы сильно переоценили количество решений. Только 88 команд решили хотя бы один таск, и из-за этого награда за решение легких тасков снижалась слишком медленно. К концу игры самый легкий таск с 76 решений стоил 2216 очков - всего лишь в 2.25 раз (44%) меньше самого сложного (5000 очков).
Мы не стали менять параметры скоринга во время игры, потому что это могло иметь гораздо худшие последствия в плане реакции участников. Впрочем, принципиально исход квалификаций это не изменило — самые сильные команды всё так же остались на первых местах.
В ретроспективе можно было бы предположить, что процент решений не превысит результат прошлого года (53 решения/~120 команд = 44%), но в этом году процент решений упал очень сильно — до 30%, хотя сложность тасков по нашей оценке не сильно изменилась.
Вывод: проведите оценку потенциального количества решений на основе данных предыдущих лет и опыта аналогичных ctf.
Мало реверса/крипты/etc?
Исторически сложилось так, что в нашей команде нет людей, которые бы хорошо разбирались в некоторых темах, и при этом могли писать таски. Поэтому мы постарались сделать базовые таски в этих категориях в меру своих возможностей, чтобы занять участников, которые хороши в них.
Впрочем, практика показала, что невозможно сделать CTF, который был бы идеален для всех. Недовольных всегда будет слышно громче, потому что у людей, которые всем довольны, обычно нет причин писать об этом. Позднее в отзывах мы увидели людей, которые благодарили организаторов за то, что было так много веба.
Вывод: смиритесь.
Заключение
Хотя CTF и кажется многим развлечением, проведение крупного CTF сопряжено с заботой о большом количестве деталей технического и организационного плана.
В этом году мы столкнулись с новыми трудностями, главная из них — сильно возросшее число участников. Несмотря на это, мы смогли оперативно решить возникшие проблемы, и достойно провести соревнования и сделать правильные выводы.